Azure Synapse Analytics – Serverless SQL Pool
Following on from our Director of Data Science & Analytics blog on how Azure Synapse Analytics went GA, Sandeep Sohal takes a closer look at one of the new capabilities Synapse SQL.
Introduction
As you may have already noticed on the 3rd of December 2020, Azure Synapse Analytics went GA, our Director of Data Science & Analytics Jonathan Scott has written a great overview in his blog post here.
Although there are a plethora of new capabilities that have gone to GA in Synapse we have for this blog post focused on Synapse SQL. Synapse SQL gives Azure Synapse Analytics workspace users the ability to do SQL based analytics at scale. We see that there are nuances to using this from a technical perspective, also potential for substantially changing cost model in azure for SQL workloads.
Synapse SQL has two consumption models. Dedicated SQL pools, where you can provision a SQL pool at a unit of scale, scale the service up or down and pause it during non-operational hours. The other is serverless SQL pool, where you do not need to provision a server, it auto-scales and you consume the service on a pay-per-query cost model. A workspace can have more than one dedicated SQL pool and only ever one serverless SQL pool. Which resource type you use is determined by the cost model that suits you and your computing needs.
We are going to take a closer look at one element of Synapse SQL the serverless SQL pool, why you might use it, the architecture, cost and how you use it to query data in different Azure storage sources.
Why use the serverless SQL pool?
By default, each Synapse workspace that you create comes with a serverless SQL pool endpoint. In Synapse Studio under Manage>SQL Pools you will see a pool called “Built-In”; this is your serverless SQL pool as shown below.
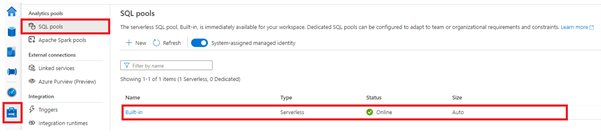
Due to the nature of the SQL pool being serverless, there is no infrastructure to set up or cluster to maintain, it auto-scales to meet your query needs and you can start querying data stored in Azure Storage as soon as you have created a Synapse workspace.
As you can appreciate there will be numerous use cases for the use of a serverless SQL Pool, below are sample use cases:
- Explore and discover data in Azure Storage quickly and on-demand.
- Create a Logical data warehouse by creating transformation views in a metadata store for up to data, directly querying from your raw ADLS Gen2 (Data Lake) storage layer.
- Simple data transformation of data in Azure Storage for use in other BI systems.
- Build data visualisation layers in Power BI, directly querying against Spark Tables.
Ultimately the decision to use the serverless SQL pool will come down to individual uses cases and cost vs benefit analysis. Is the optimal option serverless SQL pool or would a dedicated resource like dedicated SQL pools be a better choice for particular workloads.
Architecture
Serverless SQL pool uses a scale-out architecture to distribute processing across multiple nodes like dedicated SQL pools. And like dedicated SQL pools, compute and storage are separate from one another, this is what allows compute to scale independently of your data.
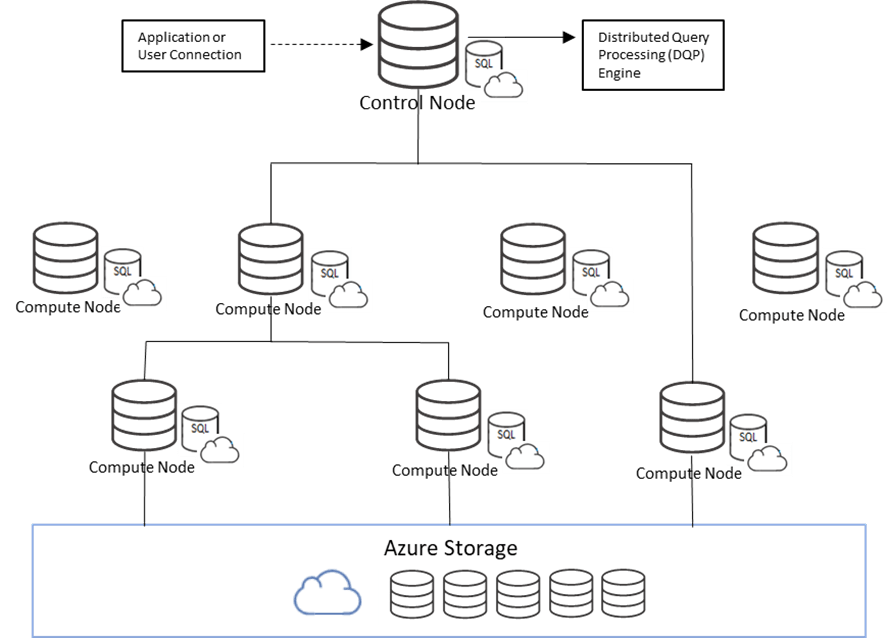
One of the key differences in architecture between the two Synapse SQL services is that dedicated SQL pools compute power is determined by the provisioned unit of scale known as data warehouse units (DWU), and queries are distributed in parallel across compute nodes using a Massively Parallel Processing (MPP) engine. A serverless SQL pool on the other hand uses a Distributed Querying Processing (DQP) engine which assigns Tasks to compute nodes to complete a query. In the diagram below a query is passed to the central Control Node that uses DQP. Four compute nodes were needed to complete the query based on the number of Tasks determined by the DQP engine. This is what allows serverless SQL pool to scale automatically to accommodate any querying requirement.
Cost
Serverless SQL pool uses a pay-per-query costing model. Cost is calculated per TB of data processed by the queries that you run. This is unlike dedicated SQL pools where you pay for a reserved resource at a pre-determined scale. Current approx. pricing for serverless SQL pool is £3.73 per TB data processed, so costs can quickly escalate if the queries processed are over very large multi TB datasets.
If the thought of end-users unwittingly running massive queries using a pay-per-query costing model scares you, there is a way to manage spend. The Cost Control feature in Synapse enables you to set budgets on the amount that can be spent on a daily, weekly, or monthly basis, and can be configured either through Synapse Studio or through the stored procedure in T-SQL.
To configure a budget In Synapse Studio you need to navigate to Manage->SQL Pools and click on the Cost Control icon for the “Built-In” serverless pool as shown below.
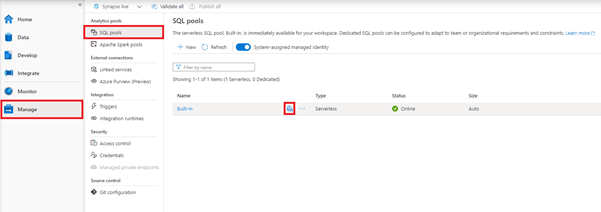
This will bring up the Cost Control configuration screen as shown below. Here budgets can be configured in terms of TB per day, week, or month. You also get a view of actual spend in terms of the amount of data that has been processed. This can be useful to see when budget limits might be close to being reached.
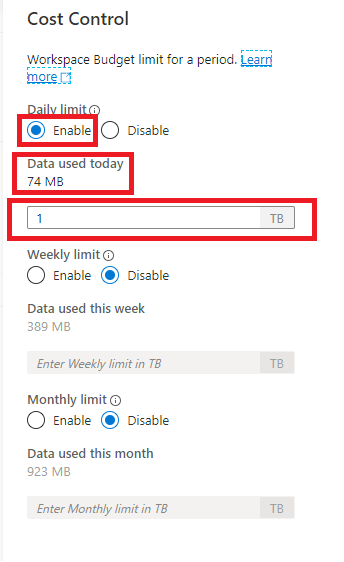
The drawback with the Cost Control feature is that limits can only be configured for an entire serverless SQL pool per workspace. This suggests that if want more granular control over costs, you may need to create multiple workspaces to manage costs per departmentteam etc.
Querying
With the serverless SQL pool, you can query data stored in ADLS Gen2 (Data Lake), Azure Blob Storage, Cosmos DB and Spark Tables using T-SQL. File formats supported include Parquet, CSV and JSON.
You are provided with a serverless SQL pool endpoint when you create a Synapse workspace and a familiar T-SQL language. Therefore any client tool that can establish a SQL TDS connection can connect to and query data using the serverless SQL pool. This includes Synapse Studio, SQL Server Management Studio, Azure Data Studio, Azure Analysis Services and Power BI.
The familiar T-SQL OPENROWSET function is provided so that you can query your primary Data Lake associated with your workspace or external Azure storage data sources. Useful features like automatic schema inference allow you to read Parquet files without having to declare column names in your query. Below is an example query that queries data from the publicly available New York Taxi dataset.

What is exciting is the ability to read Spark Tables using T-SQL syntax without the need to provision a Spark Cluster, pay for the reserved resource, wait for it to start up and then execute a SQL query. With the serverless SQL pool, you can query a Spark Table in seconds as opposed to minutes, and with connectivity to Power BI, this opens a whole new possibility of powerful data visualisations and quicker data insights.
There are limitations to the T-SQL that you can use with the serverless SQL pool. For further details on what T-SQL is supported by serverless SQL pool, please refer to the following Microsoft article here.
For more information, please do not hesitate to get in touch with our experts.
Свързани новини
Expertise
Where is the construction industry heading on its digital journey?
Our author Sabrina Hilmer explores what’s moving the industry. The construction industry has now reached the point of intensively dealing…
Expertise
Can we improve margins in the construction sector?
Construction is renowned for competitive pricing and tight margins, which the industry has been trying to improve for years. Faced…